
W tym wpisie przyjrzymy się funkcji agregującej COLLECT. Funkcja ta przyjmuje jako argument kolumnę, zwracając w wyniku zagnieżdżoną tabelę dla każdej grupy, po której odbywa się grupowanie. Tabela ta zawiera wiersze złożone z wartości kolumny, która została podana jako argument. Wiersze zawarte w zagnieżdżonej tabeli, przynależą do grupy, dla której wywołana została funkcja (rys. 1.)

Pełny opis i składnia funkcji dostępna jest w dokumentacji:
https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/COLLECT.html#GUID-A0A74602-2A97-449B-A3EC-847D38D3DA90)
Przykładowy przypadek użycia 1: różne poziomy agregacji w jednym zapytaniu.
Funkcję COLLECT można użyć w celu zwrócenia w jednym zapytaniu wyników o różnych poziomach agregacji.
Na początku spójrzmy na przykład bez wykorzystania funkcji COLLECT. Chcemy obliczyć średnią pensję dla departamentu wg dwóch algorytmów:
- V1 – średnia pensja dla departamentu
- V2 – średnia pensja dla departamentu wyliczana ze średnich pensji dla poszczególnych stanowisk w ramach departamentu, np. jeśli w departamencie jest jeden kierownik, czterech sprzedawców i dwie osoby odpowiedzialne za administracje, to średnia V2 będzie średnią wyliczoną ze średniej pensji na stanowisku kierownika, średniej pensji na stanowisku sprzedawcy, średniej pensji na stanowisku administracyjnym.
select d.department_name
,to_char(avg(e.salary),'999G999D00') as dept_salary_avg_v1
,(select to_char(avg(dept_job_salary_avg),'999G999D00')
from (
select d_i.department_id
,e_i.job_id
,avg(e_i.salary) as dept_job_salary_avg
from hr.employees e_i
join hr.departments d_i on d_i.department_id = e_i.department_id
where d_i.department_id = d.department_id
group by d_i.department_id,e_i.job_id
)
group by department_id
) as dept_salary_avg_v2
from hr.employees e
join hr.departments d on d.department_id = e.department_id
group by d.department_id, d.department_name
order by 1;
Jak możemy zrobić to przy użyciu funkcji COLLECT? W tym celu utwórzmy dwa typy bazodanowe, które są potrzebne w kolejnym zapytaniu:
create or replace type job_salary as object ( job_title varchar2(35) ,salary number ) / create or replace type job_salary_tab as table of job_salary; /
Następnie możemy skorzystać z funkcji COLLECT:
select department_name
,to_char(dept_salary_avg_v1,'999G999D00') as dept_salary_avg_v1
,(select to_char(avg(avg(salary)),'999G999D00')
from table(dept_job_sal) group by job_title) as dept_salary_avg_v2
from (
select d.department_name
,avg(salary) as dept_salary_avg_v1
,cast(collect(job_salary(job_title,salary)) as job_salary_tab) as dept_job_sal
from hr.employees e
join hr.jobs j on j.job_id = e.job_id
join hr.departments d on d.department_id = e.department_id
group by d.department_name
)
order by 1;
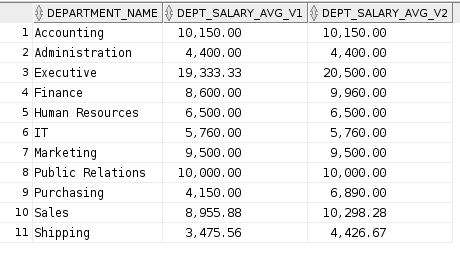
Podobne rezultaty można oczywiście osiągnąć na różne sposoby. Niemniej funkcja COLLECT może być bardzo użyteczna np. gdy mamy duże skomplikowane zapytanie, w którym trudno szybko zmienić poziom agregacji. Dzięki wykorzystaniu funkcji COLLECT możemy zrobić to w stosunkowo prosty sposób, nie ingerujący mocno w główne zapytanie.
Przykładowy przypadek użycia 2: agregacja danych znakowych.
Ciekawym przypadkiem użycia jest agregacja danych znakowych z wykorzystaniem typów i funkcji z Oracle Application Express (APEX). Tym sposobem uzyskujemy efekt działania funkcji LISTAGG wraz z możliwością skorzystania z opcji DISTINCT. Funkcja LISTAGG nie pozwala na użycie w niej DISTINCT.
select d.department_name
,listagg(distinct j.job_title,', ')
within group (order by j.job_title) as job_titles_1
,apex_string.join(cast(collect(distinct j.job_title) as apex_t_varchar2),', ') as job_titles_2
from hr.employees e
join hr.jobs j on j.job_id = e.job_id
join hr.departments d on d.department_id = e.department_id
group by d.department_name;
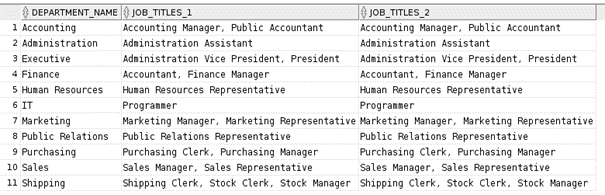
Autorzy:
Tomasz Strawski
Rafał Stryjek